错题脑图:选择题公式先背这个
题 1:银行家算法安全序列
文字版原题
系统中有三类互斥资源 R1、R2、R3,可用资源数分别为 9、8、5。T0 时刻有 P1、P2、P3、P4、P5 五个进程,题目给出各进程对资源的最大需求量和已分配资源数。若进程按某一序列执行,问哪个序列能使系统处于安全状态。

答案:C,P2 → P4 → P5 → P1 → P3
这类题不是凭感觉看序列,而是严格做三步:算可用资源 Available,算每个进程还需要 Need,再按选项顺序模拟执行。
第一步:算 Available
资源总量:R1=9,R2=8,R3=5。
已分配合计:R1 = 1+2+2+1+1 = 7;R2 = 2+1+1+2+1 = 7;R3 = 1+1+0+0+3 = 5。
所以当前可用资源:Available = (9,8,5) - (7,7,5) = (2,1,0)。
第二步:算 Need = Max - Allocation
| 进程 | 最大需求 | 已分配 | 还需要 Need | 初始能否执行 |
|---|---|---|---|---|
| P1 | (6,5,2) | (1,2,1) | (5,3,1) | 不能,R3 不够。 |
| P2 | (2,2,1) | (2,1,1) | (0,1,0) | 能,Need ≤ (2,1,0)。 |
| P3 | (8,1,1) | (2,1,0) | (6,0,1) | 不能,R1/R3 不够。 |
| P4 | (1,2,1) | (1,2,0) | (0,0,1) | 不能,R3 不够。 |
| P5 | (3,4,4) | (1,1,3) | (2,3,1) | 不能,R2/R3 不够。 |
第三步:模拟执行 C 选项
- 初始 Available = (2,1,0),只有 P2 可执行。P2 完成后释放 (2,1,1),Available = (4,2,1)。
- P4 Need=(0,0,1),可执行。释放 (1,2,0),Available = (5,4,1)。
- P5 Need=(2,3,1),可执行。释放 (1,1,3),Available = (6,5,4)。
- P1 Need=(5,3,1),可执行。释放 (1,2,1),Available = (7,7,5)。
- P3 Need=(6,0,1),可执行。安全序列成立。
银行家算法口诀:先可用,后需求;能跑就释放;一路跑完才安全。
题 2:三个可靠度 0.8 的部件串联
文字版原题
三个可靠度 R 均为 0.8 的部件串联构成一个系统,求该系统的可靠度。
答案:B,0.512
题中三个部件是串联。串联系统的特点是:任何一个部件失败,整个系统失败。所以系统可靠度等于各部件可靠度相乘。
串联可靠度:R = R1 × R2 × ... × Rn
本题:0.8 × 0.8 × 0.8 = 0.512。
扩展:并联系统怎么做
如果题目画的是并联,即多个部件只要有一个成功系统就成功,那么应先算全部失败概率,再用 1 减掉。
并联可靠度:R = 1 - (1-R1)(1-R2)...(1-Rn)
题 3:分页存储逻辑地址转物理地址
文字版原题
页式存储系统的逻辑地址由页号和页内地址组成。页面大小为 4K,逻辑地址用十进制表示。图中逻辑地址为 8644,页表中页号 0、1、2 分别对应物理块号 2、3、8。求转换后的十进制物理地址。
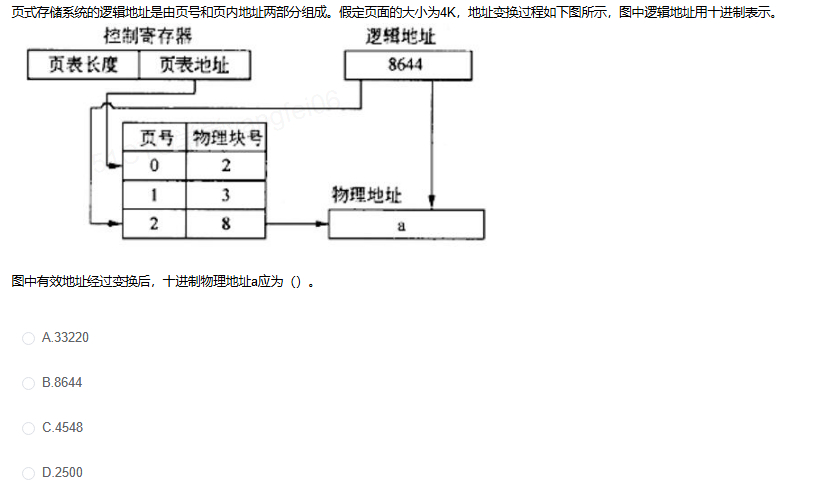
答案:A,33220
分页地址转换题核心只有两个数:页号和页内偏移。页大小 4K 要按 4096 字节计算。
计算过程
- 页面大小 = 4K = 4096 字节。
- 逻辑地址 = 8644。
- 页号 =
8644 ÷ 4096 = 2,余数为8644 - 4096 × 2 = 452。 - 查页表:页号 2 对应物理块号 8。
- 物理地址 = 物理块号 × 页大小 + 页内偏移 =
8 × 4096 + 452 = 33220。
分页公式:逻辑地址 = 页号 × 页大小 + 页内偏移;物理地址 = 块号 × 页大小 + 页内偏移。
题 4:链接文件分配,访问第 5120 逻辑字节
文字版原题
某文件系统采用链式存储管理方案,磁盘块大小为 1024 字节。文件 Myfile.doc 由 5 个逻辑记录组成,每个逻辑记录大小与磁盘块大小相等,并依次存放在 121、75、86、65、114 号磁盘块上。若要读取文件的第 5120 逻辑字节处的信息,应访问几号磁盘块?
答案:D,114 号磁盘块
文件采用链接存储,5 个逻辑记录依次放在 121、75、86、65、114 号磁盘块,每块 1024 字节。要找第 5120 个逻辑字节属于第几个逻辑块。
计算过程
每个磁盘块 1024 字节:
- 第 1 块:第 1 到 1024 字节,对应磁盘块 121。
- 第 2 块:第 1025 到 2048 字节,对应磁盘块 75。
- 第 3 块:第 2049 到 3072 字节,对应磁盘块 86。
- 第 4 块:第 3073 到 4096 字节,对应磁盘块 65。
- 第 5 块:第 4097 到 5120 字节,对应磁盘块 114。
所以第 5120 个逻辑字节在第 5 个逻辑记录中,对应 114 号磁盘块。
第 n 个字节所在块号 = ceil(n / 块大小)。本题 ceil(5120 / 1024) = 5。
题 5:软件架构设计活动,错误的是哪项
文字版原题
软件架构设计包括提出架构模型、产生架构设计和进行设计评审等活动,是一个迭代过程。以下关于软件架构设计活动的描述,错误的是哪一项?
答案:C
错误点在“设计并实现这些构件”。架构设计可以识别、设计、集成构件,定义接口和关系,但“实现构件”属于详细设计和编码阶段。
逐项判断
| 选项 | 判断 | 原因 |
|---|---|---|
| A 初期选择合适架构风格 | 正确 | 架构设计早期要根据质量属性选择分层、事件驱动、微服务等风格。 |
| B 将已标识构件映射到架构中并分析关系 | 正确 | 构件、连接件和依赖关系是架构设计的重要内容。 |
| C 将构件集成到架构中,设计并实现这些构件 | 错误 | 错在“实现”。架构设计不等于编码实现。 |
| D 得到详细架构设计后邀请独立人员评审 | 正确 | 架构评审需要相对独立视角识别风险和缺陷。 |
题 6:16M 字节主存按字节编址,需要多少位地址
文字版原题
如果主存容量为 16M 字节,且按字节编址,表示该主存地址至少需要多少位?

答案:C,24 位
按字节编址表示每个字节都有独立地址。16M 字节意味着需要能表示 16M 个不同地址。
计算过程
1M = 2^20,所以 16M = 16 × 2^20 = 2^4 × 2^20 = 2^24。
如果地址有 n 位,就能表示 2^n 个地址。要表示 2^24 个字节地址,至少需要 24 位。
地址位数公式:容量 / 编址单位大小 = 地址个数 = 2^n。
题 7:ABSD 采用什么描述软件架构
文字版原题
基于软件架构的设计(ABSD)强调由商业、质量和功能需求的组合驱动软件架构设计。它强调采用(1)来描述软件架构,采用(2)来描述需求。问题 1 选择哪项?
答案:B,视角与视图
ABSD 强调由商业、质量和功能需求共同驱动架构设计。描述软件架构时,采用“视角与视图”;描述需求时,采用“用例和质量属性场景”。
为什么选 B
软件架构不是一张图可以讲完的。用户、开发、测试、运维、项目经理关心的问题不同,所以需要从不同视角观察系统,并形成不同视图。例如逻辑视图看功能抽象,进程视图看并发通信,部署视图看节点拓扑。
顺手把第二空也记住
如果题目继续问“采用什么描述需求”,标准说法是:用例描述功能需求,质量属性场景描述质量需求。
题 8:阶段界限严格,应选哪种开发方法
文字版原题
某开发组在开发某个系统时,各个阶段具有严格的界限,只有一个阶段的获得认可才能进行下一个阶段的工作,则该开发组最可能采用的软件开发方法是什么?
答案:B,结构化方法
题干关键词是“各阶段有严格界限,只有一个阶段获得认可才能进入下一个阶段”。这体现的是传统结构化方法/瀑布式思想,而不是快速原型法。
为什么不是快速原型法
快速原型法强调先快速构造原型,让用户尽早反馈,再反复修改需求和设计。它的阶段边界并不严格,核心是迭代和反馈。
结构化方法的特点
- 强调自顶向下、逐步求精。
- 分析、设计、实现、测试等阶段边界清楚。
- 前一阶段成果评审通过后,再进入下一阶段。
题 9:90000H 到 CFFFFH,需要多少片 16K×8bit 芯片
文字版原题
内存按字节编址,地址从 90000H 到 CFFFFH。若用存储容量为 16K×8bit 的存储器芯片构成该内存,至少需要多少片?

答案:D,16 片
这题分两步:先算地址范围容量,再除以每片芯片容量。
第一步:算地址空间大小
地址从 90000H 到 CFFFFH,注意首尾都包含,所以容量是:
CFFFFH - 90000H + 1 = 3FFFFH + 1 = 40000H 字节
40000H = 4 × 16^4 = 262144 字节 = 256KB。
第二步:算每片芯片容量
16K × 8bit 表示有 16K 个存储单元,每个单元 8bit,也就是 1 字节,所以每片容量是 16KB。
需要芯片数:256KB ÷ 16KB = 16。
题 10:软件可靠性,不正确的是哪项
文字版原题
下列关于软件可靠性的叙述,不正确的是哪一项?

答案:A
软件可靠性可以通过运行失效数据、历史数据、开发过程数据和可靠性模型进行估算与预测。A 说“不能通过历史数据和开发数据直接测量和估算出来”,说法过绝对,因此不正确。
逐项判断
| 选项 | 判断 | 解释 |
|---|---|---|
| A 可靠性不能通过历史数据和开发数据直接测量和估算出来 | 错误 | 可靠性确实受因素影响复杂,但可以通过失效数据、历史数据和模型进行评估、预测和估算。 |
| B 可靠性是在特定环境和时间内无故障运行的概率 | 正确 | 这是软件可靠性的经典定义。 |
| C 故障指软件行为与需求不符,故障有等级之分 | 正确 | 故障可按严重程度、影响范围等划分等级。 |
| D 排除一个故障可能引入其他错误 | 正确 | 修改代码可能引入回归缺陷,所以需要回归测试。 |
可靠性定义:在规定环境、规定时间内,软件不发生失效并完成规定功能的概率。
题 11-32 深度解析
每题按”题干 → 答案 → 解题步骤 → 知识点 → 陷阱 → 口诀”标准格式展开,与前 10 题同深度。
题 11:关系代数表达式求值

解题方法
关系代数题按运算符优先级从内向外执行。
运算符优先级与含义
| 符号 | 含义 | 操作 | 例子 |
|---|---|---|---|
| σ | 选择(Selection) | 按条件挑行 | σ_{age>18}(R) → 年龄>18的行 |
| π | 投影(Projection) | 按列表挑列 | π_{name,age}(R) → 只要姓名和年龄列 |
| ⋈ | 自然连接(Natural Join) | 同名同值属性自动连接 | R ⋈ S → 相同属性的等值连接+去重列 |
| × | 笛卡尔积 | 每行列组合 | R × S → R每行与S每行拼起来 |
| ÷ | 除法(Division) | 找出R中与S全部值都匹配的 | R÷S → R中含有S所有值的那些 |
解题三步法
- 先做最内层括号里的操作(通常是选择 σ 或投影 π)
- 再做连接 ⋈ 或笛卡尔积 ×
- 最后做投影 π(从右往左读表达式)
解题口诀:σ 选行 → π 选列 → ⋈ 连接 → 从左向右做,括号先做。
题 12:函数依赖与范式判断

答案:D,2NF
关系 S(Sno, Sname, Zip, City),函数依赖:Sno → Sname, Zip, City,Zip → City。
第一步:找候选键
Sno 只在左边出现(L 类属性),且 Sno 的闭包 = {Sno, Sname, Zip, City} = 全部属性,所以 Sno 是候选键。
第二步:判断范式级别
| 级别 | 核心要求 | 本题是否满足 |
|---|---|---|
| 1NF | 属性不可再分 | 满足 |
| 2NF | 非主属性完全函数依赖于候选键 | 满足 — Sno→每个非主属性,没有部分依赖 |
| 3NF | 非主属性不传递依赖于候选键 | 不满足 — 存在 Sno→Zip→City 的传递链 |
| BCNF | 所有决定因素都是候选键 | 不满足 — Zip 可以决定 City,但 Zip 不是候选键 |
传递依赖的判断
Sno 决定 Zip,Zip 决定 City → 形成了 Sno → Zip → City 的链条。City 不是直接由候选键 Sno 决定的,而是通过 Zip 间接传递的。所以最高满足 2NF。
范式口诀:1NF 原子不可分,2NF 消除部分依赖,3NF 消除传递依赖,BCNF 所有决定因素是候选键。
题 13:三层架构中数据访问模式的选择

答案:在线访问模式(前台查询) vs 离线数据模式(后台批量)
核心知识点:两种数据访问模式对比
| 维度 | 在线访问模式 (Online) | 离线数据模式 (Offline/Dataset) |
|---|---|---|
| 连接方式 | 保持数据库连接,实时操作 | 断开模式,批量操作后一次性提交 |
| 适用场景 | 用户交互、前台查询、实时响应 | 批量更新、报表生成、后台任务 |
| 事务 | 短事务 | 长事务/批处理 |
| 并发冲突 | 乐观锁/悲观锁 | 批处理后可能冲突需检测 |
| 数据新鲜度 | 实时数据 | 可能过时,需刷新 |
本题分析:网上书店前台 — 用户查询书籍、下单需要实时响应 → 在线访问模式。后台 — 批量更新库存、维护日志、生成报表 → 离线数据模式(DataSet),避免长事务锁表影响前台。
题 14:UML 依赖关系的语义

答案:A 使用 B(B 的变化可能影响 A)
UML 类图中,虚线箭头表示依赖(Dependency)。
六种类图关系按耦合强度从强到弱
| 关系 | UML 表示 | 语义 | 代码体现 | ”掰了会怎样” |
|---|---|---|---|---|
| 泛化 Generalization | 实线 + 空心三角箭头 | 继承,is-a | extends | 子类消失 |
| 实现 Realization | 虚线 + 空心三角箭头 | 实现接口 | implements | 实现类不能用 |
| 组合 Composition | 实线 + 实心菱形 | 强拥有,同生命周期 | 成员对象 new 在内部 | 部分随之消亡 |
| 聚合 Aggregation | 实线 + 空心菱形 | 弱拥有,可独立存在 | 成员由外部传入 | 部分可以独立存活 |
| 关联 Association | 实线 | 结构关系,知道对方 | 成员变量 | 关系断开 |
| 依赖 Dependency | 虚线箭头 | 使用关系,临时调用 | 方法参数/局部变量 | 调用失败 |
本题分析:A 虚线箭头指向 B → A 依赖 B → A 使用 B。B 的接口变化会导致 A 也需要修改。
记忆:泛化实三角,实现虚三角;组合实心菱,聚合空心菱;关联是实线,依赖是虚箭。
题 15:数据库完整性约束分类

答案:参照完整性、实体完整性、用户定义完整性
三大数据库完整性约束
| 约束类型 | 定义 | 实现方式 | 典型考题表述 |
|---|---|---|---|
| 实体完整性 | 主键不能为空且唯一 | PRIMARY KEY / UNIQUE NOT NULL | ”主标识不能为空且唯一” |
| 参照完整性 | 外键要么为空,要么等于被参照表主键的某个值 | FOREIGN KEY REFERENCES | ”XX 字段引用员工表的主键” |
| 用户定义完整性 | 业务规则约束 | CHECK / NOT NULL / DEFAULT / 触发器 | ”仓库地址不能为空” “年龄大于 0” |
本题分析:① employeeID 引用员工表 → 参照完整性(外键约束) ② 主标识唯一且非空 → 实体完整性(主键约束) ③ 仓库地址不能为空 → 用户定义完整性(业务规则约束)
记忆口诀:主键实体,外键参照,CHECK 是用户定义。
题 16:中介者模式 (Mediator Pattern)

答案:中介者模式 (Mediator)
题干关键词:”多个对象行为相互影响”、”不希望对象之间直接引用”、”集中协调”。这正是中介者(Mediator)模式的经典描述。
中介者模式详解
- 意图:用一个中介对象封装一系列对象的交互,避免对象间显式相互引用。
- 结构:Colleague → Mediator ← Colleague(同事类不互相通信,只和中介者通信)
- 优点:将网状依赖变为星型依赖,降低耦合。
- 缺点:中介者可能成为系统的复杂中心。
- 典型场景:聊天室(用户通过聊天室通信)、GUI 窗格协调、航班调度塔台、微服务编排器。
不要和以下模式混淆
| 模式 | 区别 |
|---|---|
| 观察者 Observer | 一对多通知,没有”协调”概念。对象 A 变化后自动通知 B/C/D。 |
| 外观 Facade | 提供简化接口,不控制交互。只是简化调用,不协调内部对象怎样交互。 |
| 职责链 Chain | 沿链传递请求直到被处理,对象之间还有前后关系。 |
题 17:代理模式 — 虚拟代理延迟加载

答案:代理模式 (Proxy) — 虚拟代理
题干关键词:”对象创建开销大”、”不希望立刻加载”、”用轻量对象代替真实对象”。”延迟加载/按需创建”是虚拟代理的核心特征。
代理模式的三种类型
| 类型 | 作用 | 考试关键词 |
|---|---|---|
| 虚拟代理(Virtual Proxy) | 延迟创建开销大的对象,需要时才创建 | ”开销大/延迟加载/先占位” |
| 远程代理(Remote Proxy) | 为远程对象提供本地代表 | ”不同地址空间/网络/RPC” |
| 保护代理(Protection Proxy) | 控制对原始对象的访问权限 | ”权限控制/访问控制” |
不要把代理和以下模式搞混
| 模式 | 核心差异 |
|---|---|
| 适配器 Adapter | 接口转换——已有的接口不匹配,包一层让两个接口兼容。 |
| 装饰 Decorator | 动态添加功能——同一个接口下层层包裹增强功能。 |
| 桥接 Bridge | 抽象与实现分离——两个维度独立变化。和”延迟加载”没关系。 |
题 18:用例 include 关系

答案:包含关系 (include)
题干关键词:”两个用例都需要执行验证客户账号这一公共行为”。
用例三种关系深度对比
| 关系 | UML 符号 | 语义 | 谁是必须的 | 箭头方向 | 考试关键词 |
|---|---|---|---|---|---|
| include | <<include>> 虚线箭头 | 基用例必然执行被包含用例 | 被包含用例 100% 执行 | 基用例 → 被包含用例 | ”都需要”/”公共步骤”/”一定” |
| extend | <<extend>> 虚线箭头 | 扩展用例在特定条件下插入基用例 | 扩展用例条件触发 | 扩展用例 → 基用例 | ”可选”/”条件触发”/”可能” |
| 泛化 | 实线 + 空心三角 | 子用例继承父用例行为 | 子用例可以覆盖 | 子用例 → 父用例 | ”多种方式”/”不同的XX” |
箭头方向速记:include 箭头从基用例指向被包含用例(指向公共步骤);extend 箭头从扩展用例指向基用例(指向被扩展的用例)。
口诀:include 必执行箭头指被含,extend 条件触发箭头指基用例。
题 19:I/O 控制方式 CPU 占用对比

答案:程序查询(轮询)方式最占 CPU
四种 I/O 方式 CPU 参与度从高到低
| 方式 | CPU 角色 | 数据传送控制 | CPU占用 | 适用 |
|---|---|---|---|---|
| 程序查询(轮询) | 全程反复检查状态 + 传送数据 | CPU 直接控制 | 最高,CPU 空转等待 | 简单嵌入式、单任务系统 |
| 程序中断 | 设备准备好后发中断,CPU 响应并传送 | CPU 直接控制 | 中等,CPU 可做其他事 | 中低速外部设备 |
| DMA | 仅在开始和结束时介入 | DMA 控制器(DMAC) | 低,批量数据由 DMAC 搬运 | 磁盘、高速网络 |
| 通道(I/O Processor) | 几乎不干预 | 通道(专有处理器) | 最低,通道是独立 CPU | 大型机多设备并发 |
DMA 传送过程
- CPU 设置 DMA 控制器(源地址、目标地址、字节数)
- DMAC 通过总线请求接管总线(周期窃取)
- DMAC 直接在内存和设备间搬运数据
- 传送完成后 DMAC 发中断通知 CPU
CPU 占用排序:轮询 >> 中断 >> DMA >> 通道
题 20:面向对象分析到设计的转换

答案:以需求模型为输入,输出设计模型
面向对象开发三阶段
| 阶段 | 输入 | 输出 | 关注点 |
|---|---|---|---|
| OOA 面向对象分析 | 业务需求、用例 | 需求模型(领域模型、用例模型) | 问题域 — “做什么” |
| OOD 面向对象设计 | 需求模型(分析产物) | 设计模型(类图、序列图、构件图、部署图) | 解空间 — “怎么做” |
| OOP 面向对象编程 | 设计模型 | 可运行代码 | 实现 — “写出来” |
设计模型包含的内容:设计类图(含属性和方法)、序列图(交互细节)、构件图(模块划分)、部署图(物理拓扑),以及设计模式的选择和应用。
题 21:Cache 与主存地址映射由什么实现

答案:全部由硬件实现
Cache 与主存之间的地址映射/变换是由纯硬件自动完成的,对程序员和操作系统透明。软件不需要也看不到 Cache 的存在。
三种 Cache 映射方式
| 映射方式 | 主存地址结构 | 硬件怎么找 | 冲突概率 |
|---|---|---|---|
| 直接映射 | [标记 | Cache行号 | 块内地址] | 取中间字段定位行号,比较标记位 | 高(同一个行号的不同块会打架) |
| 全相联映射 | [标记 | 块内地址] | 同时比较所有行标记(需相联存储器) | 低(任意块可放任意行) |
| 组相联映射 | [标记 | 组号 | 块内地址] | 组内全相联比较(折中方案) | 中等(同组不同块可共享) |
典型计算题示例
主存 4GB(32 位地址),Cache 64KB,块大小 64B,4 路组相联:
- 块内偏移 = log₂(64) = 6 位
- Cache 总行数 = 64KB / 64B = 1024
- 组数 = 1024 / 4 = 256 组
- 组号 = log₂(256) = 8 位
- 标记 = 32 - 8 - 6 = 18 位
记忆:Cache 对程序员透明 → 全部硬件自动完成。
题 22:流水线加速比计算

B,1.75(需按截图中的段数和任务数确认)
流水线加速比标准计算
加速比 = 顺序执行总时间 / 流水执行总时间
顺序执行总时间:每条指令依次执行,总时间 = 指令数 × 各段时间和
流水执行总时间:第一条指令完整流经各段 + 后续指令每隔一个周期(最长段)流入
T_pipeline = Σ(各段时间) + (N - 1) × max{各段时间}
示例计算(4 段,段时分别为 2, 3, 2, 1 ns,10 条指令):
- 周期 = max{2,3,2,1} = 3ns
- Σ各段 = 2+3+2+1 = 8ns
- 顺序时间 = 10 × 8 = 80ns
- 流水时间 = 8 + (10-1)×3 = 8 + 27 = 35ns
- 加速比 = 80/35 ≈ 2.29
如果截图算出来是 1.75,说明:可能指令数较少(比如 4 条指令),或者流水段数较少。加速比随指令数增大趋近于”各段和/最长段”。
流水线性能三大指标
吞吐率 = 指令数 / 流水线执行时间
效率 = 实际加速比 / 最大可能加速比(=段数)
题 23:系统性能评价方法

答案:含有绝对化表述的选项通常是错误选项
常见性能评价方法
| 方法 | 内容 | 优点 | 缺点 |
|---|---|---|---|
| Benchmark 基准测试 | 用标准测试程序集评测系统 | 接近真实负载,可横向比较 | 受 CPU/内存/IO/编译器等综合影响 |
| MIPS | 每秒百万指令(Million Instructions Per Second) | 直观 | 不同指令集不可比,受代码优化影响大 |
| MFLOPS | 每秒百万浮点运算 | 适合科学计算 | 不能反映整数性能 |
| SPEC | 标准性能评估组织发布的综合基准 | 行业标准 | 测试套装复杂 |
真题陷阱规律:出现”只取决于”、”完全不受影响”、”仅测量”这类绝对化表述时,该选项通常是错误项。因为计算机系统性能由 CPU、Cache、主存、I/O、操作系统、编译器、网络等多方面共同决定。
题 24:网桥与交换机的本质关系

答案:交换机是一种多端口网桥
网桥 vs 交换机 vs 路由器 vs 集线器
| 设备 | 工作层 | 转发依据 | 隔离冲突域 | 隔离广播域 |
|---|---|---|---|---|
| 集线器 Hub | 物理层 L1 | 广播到所有端口 | 否 | 否 |
| 网桥 Bridge | 数据链路层 L2 | MAC 地址表 | 是 | 否 |
| 交换机 Switch | 数据链路层 L2(多数) | MAC 地址表 | 是 | 否(VLAN可隔离) |
| 路由器 Router | 网络层 L3 | IP 路由表 | 是 | 是 |
核心考点:”交换机本质上是一种多端口网桥”几乎是历年真题的固定正确选项。两者都根据 MAC 地址转发帧,都在数据链路层。
记忆:S witch = multi-port bridge(交换机=多端口网桥);Router 才看 IP(路由器看IP)。
题 25:MD5 报文摘要算法

答案:MD5 属于报文摘要算法(Message Digest)
密码学三大类算法
| 类别 | 代表算法 | 特点 | 密钥 | 典型用途 |
|---|---|---|---|---|
| 对称加密 | DES/3DES/AES/RC4/SM4 | 加解密同密钥,速度快 | 1 个(共享密钥) | 大批量数据加密、通信加密 |
| 非对称加密 | RSA/ECC/ElGamal/SM2 | 公钥加密私钥解密,速度慢 | 2 个(公私钥对) | 数字签名、密钥交换、身份认证 |
| 摘要(哈希) | MD5/SHA-1/SHA-256/SM3 | 定长输出,不可逆,雪崩效应 | 无(无密钥) | 完整性校验、数字指纹、密码存储 |
MD5 vs SHA:MD5 输出 128 位,已发现碰撞漏洞,不推荐用于安全场景。SHA-256 输出 256 位,目前安全。软考中 MD5 = 报文摘要 = 不是加密。
记忆:MD5/SHA = 摘要 = Digest = 无密钥 = 不可逆 ≠ 加密(加密可逆)。
题 26:OSI 层次故障定位

逐层定位:电缆/EIA → 物理层,MAC/帧 → 数据链路层,IP/路由 → 网络层
OSI 七层排障关键词速查表
| OSI 层 | 排障关键词 | 检查内容 |
|---|---|---|
| 物理层 | 线缆、EIA、RJ45、电信号、光纤、接口状态(up/down)、电压 | 线缆是否插好、端口是否 UP |
| 数据链路层 | MAC、帧、CRC 错误、协议状态(保持活动/建立)、VLAN | MAC 地址学习、帧是否丢弃 |
| 网络层 | IP、路由表、子网、Ping、Traceroute、ICMP | 路由是否可达、IP 配置 |
| 传输层 | TCP/UDP、端口、连接状态、SEQ/ACK | 端口是否监听、连接是否建立 |
| 应用层 | HTTP/DNS/FTP、应用日志 | 应用返回的错误码 |
真题速判规则:
- 看到”电缆、电压、接口 show ip int brief 显示 down” → 物理层问题
- 看到”MAC、帧丢弃、VLAN” → 数据链路层问题
- 看到”IP 不可达、路由不通” → 网络层问题
题 27:以太网交换机深入考点

答案:以太网交换机从工作原理上是一种多端口网桥
交换机核心知识点
- 学习:记录源 MAC 地址和端口号到 MAC 地址表
- 转发:查 MAC 地址表,找到目标端口则独发,找不到则泛洪
- 过滤:同端口不转发
冲突域与广播域辨析
| 设备 | 冲突域 | 广播域 |
|---|---|---|
| 集线器 | 同一个(所有端口共享) | 同一个 |
| 网桥/交换机(无VLAN) | 每个端口独立一个 | 同一个 |
| 交换机(有VLAN) | 每个端口独立一个 | 每个 VLAN 一个 |
| 路由器 | 每个端口独立一个 | 每个端口一个 |
题 28:PV 操作与前驱图同步

答案:C,V(S1)、V(S2)
前驱图中 P1、P2 先于 P3 执行。每个箭头代表一个同步信号量。
PV 操作前驱图同步标准解法
规则:
- 每条箭头的起点进程执行结束后,对信号量执行 V(释放)
- 每条箭头的终点进程执行前,对信号量执行 P(申请)
- 每个箭头分配一个独立的信号量,初始值为 0
本题分析:P1 → P3 箭头对应 S1,P2 → P3 箭头对应 S2。P1 完成后执行 V(S1),P2 完成后执行 V(S2)。P3 开始前需要先执行 P(S1) 和 P(S2),确保两个前驱都完成。
PV 操作值变化跟踪
- S1=S2=0(初始为 0)
- P1 执行完 → V(S1),S1 变为 1
- P2 执行完 → V(S2),S2 变为 1
- P3 的 P(S1) 能通过(S1>=1),S1 变为 0
- P3 的 P(S2) 能通过(S2>=1),S2 变为 0
- P3 开始执行
口诀:前驱 V 释放,后继 P 等待;看箭头方向,尾 V 头 P。
题 29:命令模式角色识别

答案:Invoker 是 MenuItem;ConcreteCommand 是 Open/AddGroup 等具体命令类
命令模式五角色
| 角色 | 职责 | 本题对应类 | 考试识别关键词 |
|---|---|---|---|
| Invoker 调用者 | 持有命令对象,触发命令执行 | MenuItem | ”菜单项”、”按钮”、”触发者” |
| Command 抽象命令 | 声明 execute() 接口 | Command | 抽象命令类/接口 |
| ConcreteCommand 具体命令 | 绑定接收者,实现 execute() | Open/AddGroup/Copy 等 | 具体命令类名 |
| Receiver 接收者 | 知道如何执行业务逻辑 | 被操作的对象(如文档/窗口) | ”实际执行者”、”业务对象” |
| Client 客户端 | 创建命令并关联接收者 | 程序入口/初始化代码 | ”创建命令并设置接收者” |
类图特征:Invoker 持有 Command 引用;ConcreteCommand 持有 Receiver 引用并实现 Command;Receiver 独立于 Command 接口。
题 30:架构风格特征与黑板架构识别

答案:架构风格关注构件类型、连接件类型、拓扑结构、约束;第二空为黑板架构
架构风格的四要素
每种架构风格定义了一组约束,包括:
- 构件类型:系统中可以有什么样的模块/组件(如分层中的”层”、管道中的”过滤器”)
- 连接件类型:构件之间如何交互(如过程调用、事件、消息、共享数据)
- 拓扑结构:构件和连接件的组织方式(如分层中的层级、管道中的线性)
- 语义约束:使用该风格必须遵守的规则(如分层中只能相邻层通信)
黑板架构识别要点
| 特征 | 黑板架构 | 仓库风格(数据仓库) |
|---|---|---|
| 中心数据结构 | 黑板(共享工作区),结构可能复杂 | 数据中心(数据库/文件) |
| 参与方 | 多个知识源(K Source),各有所长 | 数据处理组件 |
| 触发方式 | 黑板状态变化触发知识源 | 数据变化或被动查询 |
| 求解方式 | 渐进式、协作式求解 | 流程式计算 |
| 典型应用 | 专家系统、语音识别、自然语言处理 | 数据平台、报表系统 |
题 31:工厂方法模式角色识别

答案:Creator 是 Bank,Product 是 Account
工厂方法模式四角色
| 角色 | 职责 | 本题类名 | 类图特征 |
|---|---|---|---|
| Product 抽象产品 | 定义产品接口 | Account | 被创建对象的抽象类 |
| ConcreteProduct 具体产品 | 实现产品接口 | Checking/Savings Account | 具体产品子类 |
| Creator 抽象工厂 | 声明工厂方法 | Bank | 有 createProduct() 抽象方法 |
| ConcreteCreator 具体工厂 | 实现工厂方法,创建具体产品 | CheckingBank/SavingsBank | override 工厂方法 |
类图识别要点:Creator 依赖于 Product(虚线或实线关联);ConcreteCreator 继承 Creator,关联 ConcreteProduct。看到两个并行的继承体系(工厂继承链 + 产品继承链)时,优先判断为工厂方法或抽象工厂。
工厂方法 vs 抽象工厂
| 维度 | 工厂方法 | 抽象工厂 |
|---|---|---|
| 产品数量 | 创建一个产品 | 创建一族相关产品 |
| 工厂数量 | 一个工厂方法对应一个产品 | 一个抽象工厂包含多个工厂方法 |
| 考试关键词 | ”子类决定实例化哪个类” | ”一系列/一族相关对象” |
题 32:微服务英文完形填空

答案:71 integrate、72 respond、73 autonomous、74 deployable、75 communicate
微服务英文黄金搭配(必背)
| 英文搭配 | 中文含义 | 考试位置 | 固定用法 |
|---|---|---|---|
| integrate with | 与……集成 | 常考第一空 | services integrate with other systems |
| respond to requests | 响应请求 | 常考第二空 | respond to incoming requests |
| autonomous services | 自治服务 | 描述微服务特性 | small, autonomous services |
| independently deployable | 可独立部署 | 描述部署特性 | each service is independently deployable |
| communicate with | 与……通信 | 描述服务交互 | services communicate with each other via HTTP |
| loosely coupled | 松耦合的 | 描述服务关系 | services are loosely coupled |
| scale independently | 独立扩展 | 描述扩展能力 | each service can scale independently |
英文完形填空做题步骤
- 先读空前后 5 个词,找固定搭配(如 integrate + with, respond + to, communicate + with)
- 判断词性:空位置需要动词/名词/形容词?(看句子成分)
- 排除干扰项:微服务语境下,deploy(部署) 不用 submit(提交),autonomous(自治) 用 automatic(自动) 来干扰
- 验证:读完整句看是否通顺
口诀:集成用 integrate + with,响应用 respond + to,自治 autonomous,可部署 deployable,通信 communicate + with。
32 道错题全量套路总结
| 题号 | 题型 | 解题动作 | 一句话记忆 |
|---|---|---|---|
| 1 | 银行家算法 | 算 Available,算 Need,按序试跑,完成释放。 | 能跑就释放,跑完才安全。 |
| 2 | 串联系统可靠性 | 串联乘成功率,并联 1 减全失败。 | 串联一个坏全坏,并联全坏才坏。 |
| 3 | 分页地址转换 | 商是页号,余数是偏移,查页表换块号。 | 页号换块号,偏移不变。 |
| 4 | 链接文件分配 | 先算第几个逻辑块,再沿链表找物理块。 | 逻辑第几块,链上数几步。 |
| 5 | 架构设计活动 | 区分架构设计和编码实现。 | 架构设计构件,不实现构件。 |
| 6 | 地址位数 | 容量除以编址单位,再取 2 的指数。 | 能表示几个地址,就要几位二进制。 |
| 7 | ABSD 描述方式 | 架构看视角与视图,需求看用例和质量场景。 | 视图描述架构,场景描述需求。 |
| 8 | 开发模型判别 | 阶段严格+评审通过→结构化/瀑布。 | 严格阶段不是快速原型。 |
| 9 | 存储芯片片数 | 先算地址范围,再除以单片容量。 | 尾 - 首 + 1。 |
| 10 | 软件可靠性定义 | 抓”特定环境+特定时间+无故障概率”。 | 可靠性可以估算,不能说完全不能算。 |
| 11 | 关系代数 | 先选行(σ),再连接(⋈),最后投列(π)。 | σ 选行,π 选列,⋈ 自然连接。 |
| 12 | 范式判断 | 找候选键→查部分依赖(2NF)→查传递依赖(3NF)。 | 2NF 消部分,3NF 消传递。 |
| 13 | 数据访问模式 | 前台在线(保持连接),后台离线(批处理)。 | 在线实时,离线批处理。 |
| 14 | UML 依赖关系 | 虚线箭头=使用关系=B变化影响A。 | 泛实三角,依虚箭头。 |
| 15 | 完整性约束 | 主键→实体,外键→参照,CHECK→用户定义。 | 主键实体,外键参照,规则用户定义。 |
| 16 | 中介者模式 | 不直接引用+集中协调→Mediator。 | 多对象不直接通信,由中介协调。 |
| 17 | 代理模式 | 开销大+延迟加载+占位→Virtual Proxy。 | 虚拟代理延迟加载。 |
| 18 | include 用例关系 | 公共必做步骤→include。 | include 必做,extend 可选。 |
| 19 | I/O 控制方式 | 轮询最占CPU,DMA最省。 | 轮询>>中断>>DMA>>通道。 |
| 20 | OOA→OOD 转换 | 需求模型进→设计模型出。 | 分析进设计,设计进实现。 |
| 21 | Cache 地址映射 | 纯硬件实现,对软件透明。 | Cache 透明=全部硬件自动完成。 |
| 22 | 流水线加速比 | 顺序时间/流水时间,长段定周期。 | 加速比=非流水/流水。 |
| 23 | 性能评价 | 绝对化说法(“只/完全/仅”)→通常错。 | 绝对化表述要警惕。 |
| 24 | 网桥/交换机 | 二层设备,根据MAC转发。 | 交换机=多端口网桥。 |
| 25 | MD5 分类 | Digest=摘要,不可逆,非加密。 | 摘要不是加密。 |
| 26 | OSI 排障 | 电缆/EIA→物理,MAC→链路,IP→网络。 | EIA/电气偏物理层。 |
| 27 | 交换机/冲突域 | 交换机隔离冲突域不隔离广播域。 | 路由器才隔离广播域。 |
| 28 | PV 操作前驱图 | 箭头尾V(释放),箭头头P(等待)。 | 前驱V释放,后继P等待。 |
| 29 | 命令模式角色 | MenuItem=Invoker,具体命令=ConcreteCommand。 | 菜单项触发命令对象。 |
| 30 | 架构风格/黑板 | 共享数据+多知识源+渐进求解。 | 黑板=多专家协作求解。 |
| 31 | 工厂方法角色 | Creator=Bank,Product=Account。 | 工厂创建产品。 |
| 32 | 微服务英文 | integrate+with,autonomous,deployable。 | 看固定搭配。 |
选择题四大黄金技巧
技巧一:先归类再做题
看到题先判断属于哪个科目(OS/计组/数据库/软工/网络/架构),套用该科目的公式库。不要每道题都从头推。
技巧二:绝对化表述通常错
”只取决于”、”完全”、”必然”、”一定不” → 大概率是错误选项。正确选项往往用”可以”、”可能”、”通常”。
技巧三:固定搭配秒选
交换机=多端口网桥、MD5=摘要不是加密、Cache=纯硬件、include=必做公共步骤。这些是真题标准答案句,出现就直接选。
技巧四:计算题写步骤
银行家/分页/流水线/芯片片数/地址位数 → 按公式一步步算,中间结果也写出来。容易检查也容易拿步骤分。